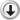فالعمر قد يكون سنه او سنه ونصف او سنه وثلاثة ارباع quantitative-continous
والطول والوزن والجرعات كذلك
اما الجنس فهو وصفي وليس كمي
Methods for Quantitative Data
الان وبعد معرفة نوعية البيانات دعونا نناقش كيفية تحليلها
بالنسبة للبينات الكمية فإن احسن الطرق لتحليلها هو قياس النزعة المركزيه Central tendency وكذك قياس مدى توزع البيانات
لقياس مدى توزع البيانات فإننا نستخدم Quantiles وهي عبارة عن الاتي:
Median: central value, that 50% of the data falls on either side
Lower Quartile: chosen to place 25% of the data below it, 75% above it
Upper Quartile:chosen to place 75% of the data below it, 25% above it
مثال من البيانات الاتيه
11 10 10 9 7 5 5 4 2
لاحظ ان المتوسطMeanوهو مقياس النزعة المركزيه هو 7 حيث يقسم الارقام الى طرفين متساويين فيكون اربع ارقام عن يمينه واربع عن شماله
Lower Quartile=4.5
حيث انها تقع بين 4 و 5 فنجمعهما ونقسمها على 2
فأين يقع Upper Quartile؟
ايضا هناك بعض المعايير الاخرى:
Maximum القيمة الكبرى
Minimum القيمة الصغرى
Median الوسيط
IQU =Inter-Quartile range حيث تجمع الربع الاول والثالث وتقسمهم على 2
نرجع للمتوسط, يأخذ منه بعض الاشتقاقات التي لاتعنيينا لنصل أخير الى ما يسمى بالانحراف المعياري
Standard Deviation
جميع القيم سالفة الذكر مهمة جدا وتجدها في أي بحث على كمي على مستوى الكرة الارضيه كلها
اهميتها:
تصف لك وضع بياناتك هل هي منحازة Skewness او معتدله مثلا
عند اخذك لعينات" مرضي مصابين بورم......" هل التقاطك للعينة صحيح هل البيانات التي اخذتها معقوله. أعرف انها سوف تشكل كثيرا ولكن مع التطبيق والامثلة سوف تجدون الامر أكثر سهولة
تطبيقات:
يهمنا كثيرا ان تكون البيانات غير منحازة ومقاربه كلها للمنتصفSymmetric distribution
If we have a symmetric distribution that means, Mean≈Median
If the data are positively skewed, Mean>Median
If the data are negatively skewed, Mean
يجب ان نعرف في النهاية ان المتوسط والانحراف المعياري اهم بكثير من باقي الاشياء, ولكن قد نحتاج الباقي!!!
مثلا عندما تكون البيانات منحازة فإنه يفضل لوصفها استخدام الوسيط والارباع والمنوال"القيمة الاكثر تكرار" لان الوسيط خاصة لا يتأثر بالقيم المنحازة كثيرا(عندما نتطرق للرسوم في الدرس المقبل تتضح الصورة أكثر)
-------
بعد أن عرفنا كيفية وصف البيانات ومعرفة نوعية توزيعها هل هو Normalاو هو skwed ،
يتأتى علينا أن نفهم النظرية الاحصائية. مامعناها؟ ولماذا استخدمها؟ وكيف اتنبأ بنتائجها؟
أحب أن أأكد مرة أخرى أنه بناء على حكمنا للبيانات من حيث انها Normalاو هو skwed ، سوف نختار الطريقة المناسبة لفرض النظرية الاحصائية ولاختيار مايسمى ب اختبار النظرية الاحصائية
سوف أطرح هنا أبسط وأكثر الطرق أستخداما لكي لا يحصل اللبس ولا تشتبه الامور
أهمية النظرية الاحصائية واختباراتها
إذا أردت عمل اي دراسة اكلينيكية او مخبريه فلابد أن تكون لديك فرضية ما!!
مثلا : البروبرانول أفضل من الكابتوبريل في خفض ضغط كبار السن!!!
هذه مثلا تعتبر فرضيه. دعني أدرسها معك وندقق فيها النظر:
اولا المجتمع(Population) الذي سوف تجرى عليه الدراسه هو" المصابين بالضغط من كبار السن والذين يأخذون أحد هذين الدوائين"
ثانيا: فرضيتي Null: نفترض أن المجموعتين متساويتين
ثالثا: الفرضية العكسية(Alternative) وهي ببساطه انه يوجد فرق بين الدوائين!!
رابعا: سوف يكون لدينا ارقام وهي عبارة عن ضغط الدم في المجموعتين باعتبار اننا نهدف مثلا الى systolic blood pressure
اذن عندها سوف نحصل على مجموعتين من الارقام الاولى تابعه للبروبرانول والمجموعه الاخرى للكابتوبريل
مجموعة البروبرانولول: 100,120,122,122,123,140,129,111,143,125,144
مجموعة الكابتوبريل: 133,123,137,135,143,137,138,130,140,136,133,129
ليس شرطا ان نحصل على نفس عدد المرضى في كل المجموعتين
هنا لكي نعرف هل فعلا هناك فرق بين الدوائين أولا، فإننا نجري اختبار الفرضية الاحصائيه
بإفتراض ان البيانات Normally distributed
فاختبار الفرضيه سوف يكون ب Two sided T-test
بغض النظر عما يعني اسم هذا الاختبار، هنا يكفى ان نعرف ان هذا الاختبار يجرى للتأكد من وجود فرق بين مجموعتين "كميتين" وليستا وصفيتين، يعني انهما يحتويان على أرقام
الذي يجري لنا الاختبار هو أحد البرامج الاحصائية حيث تدخل البيانات السابقة للبرنامج ويعطيك النتيجة في لحظات
طبعا انا عملت الاختبار لكم في برنامج Minitab وهاهي النتيجه
De******ive Statistics: Captopril; Propranolol
Variable N N* Mean SE Mean StDev Minimum Q1 Median Q3
Captopril 12 0 134,50 1,55 5,37 123,00 130,75 135,50 137,75
Propranolol 11 0 125,36 4,04 13,39 100,00 120,00 123,00 140,00
Variable Maximum
Captopril 143,00
Propranolol 144,00
بالنسبة لاختبار النظرية الاحصائيه فالنتيجة كالتالي
Two-Sample T-Test and CI: Propranolol; Captopril
Two-sample T for Propranolol vs Captopril
N Mean StDev SE Mean
Propranolol 11 125,4 13,4 4,0
Captopril 12 134,50 5,37 1,5
Difference = mu (Propranolol) - mu (Captopril)
Estimate for difference: -9,13636
95% CI for difference: (-18,55765; 0,28493)
T-Test of difference = 0 (vs not =): T-Value = -2,11 P-Value = 0,056 DF = 12
أحب أن أخبركم ان اختبار النظريه الاحصائية يسمى Null Hypothese
اذا عندنا نظريتان الاولى "نل" والاخرى النظريه العكسية
عودا للنتيجة سوف اناقش الان فقط كيف تقرأ النتيجةP-Value = 0,056
اذا كانت النتيجةP-Value اقل من 0.05 مثلا 0.001 فاننا نرفض نظريNull ونعتبرها خاطئة ونثبت النظرية العكسية
اذا كانت النتيجةP-Value اكبر من 0.05 كما هي الحال معنا فإننا نقول: لانستطيع أن نرفض نظرية" نل" وبذلك يكون
هناك فرق بين المجموعتين
وبذلك تكون قد خلصت الى ان البروبرانولول افضل فعلا من الكابتوبريل ( البيانات وهمية)
طبعا هناك اعتبارات غير نظرية "نل" وسوف أناقشها بعون الله فيما بعد
اعمل لنفسك تمرين بأن تذهب الى خلاصة اي بحث وسوف تجد فيها نظريه معينه وسوف تجد رقم
p-value
واحكم بنفسك على النتيجة قبل اكمال قراءة الخلاصة